Efficient FFT Implementations
A simple optimization, can rewrite the final loop reusing t
= wyk[1], this is a
butterfly operation.
for k Ỳ 0 to n/2 - 1
do t Ỳ wyk[1],
yk Ỳ
yk[0] + t
yk +
n/2 Ỳ yk[0] - t
w
Ỳ w wn
 Let's analyze the data used in Recursive-FFT. The figure shows where
coefficients are moved on the way down, with an initial vector of length 8.
Let's analyze the data used in Recursive-FFT. The figure shows where
coefficients are moved on the way down, with an initial vector of length 8.
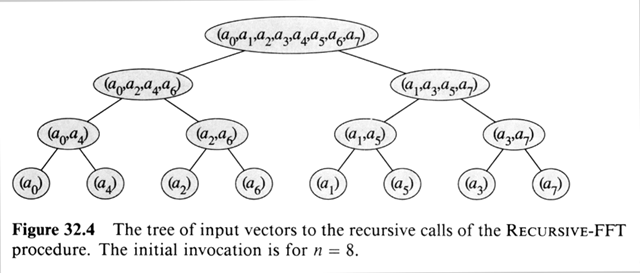
All evens move right, the odds to the left. Each Recursive-FFT
make two more calls, until we hit vectors of length 1. If instead of the
order ( a0, a1, a2, a3, a4,
a5, a6, a7 ) we could use ( a0,
a4, a2, a6, a1, a5, a3,
a7 ) then we could traverse the tree with data in place. This
algorithm would start at the bottom and work up using DFT's to take 2 1's to
a 2, 2 2's to a 4, etc. Consider the array A [ 0...n-1 ] as originally
holding a in the order of the leaves. We then iterate on the levels s, as
follows:
FFT-Base ( a )
-
n Ỳ length[a]
-
for s Ỳ 1 to lg n
-
do m Ỳ 2s
-
wm
Ỳ e(
2 p i / m )
-
for k Ỳ
to n - 1 by m
-
do w Ỳ
1
-
for j Ỳ
0 to m/2 - 1
-
do t Ỳ wA[k + j + m/2]
-
u Ỳ A[k + j]
-
A[k + j] Ỳ u + t
-
A[k + j + m/2] Ỳ u - t
-
w Ỳ wwn
This code "butterflies" up from the bottom
level. It also identifies:
A[k ...k + 2s-1
- 1] with y [0] and A[k+ 2s-1
...k + 2s - 1] with y [1]
By adding the code to put a into A[] in the right order the
code is complete.
Iterative-FFT ( a )
-
Bit-Reverse-Copy ( a, A )
-
n length[a]
-
for s Ỳ 1 to lg n
-
do m Ỳ 2s
-
wm
Ỳ e(
2 p i / m )
-
w
Ỳ 1
-
for j
Ỳ 0 to m/2 - 1
-
do for k j to n - 1 by m
-
do t Ỳ wA[k +m/2]
-
u Ỳ A[k]
-
A[k] Ỳ u + t
-
A[k + m/2] Ỳ u - t
-
w Ỳ wwn
-
return A
The trick is Bit-Reverse-Copy ( a, A ) The desired order
(with n = 8) is 0, 4, 2, 6, 1, 5, 3, 7 or in binary 000, 100, 010, 110, 001,
101, 011, 111 if we "bit reverse" 000, 001, 010, 011, 100, 101,
110, 111 we get the integers in order. This is what we need to do.
Parallel FFT Circuit
Using the idea of the iterative FT we can map this into a
parallel algorithm where each "level" is one of the lg n outer
loops as follows:

Note: there are lg n levels each doing Q
( n ) work. so in parallel this algorithm takes Q
(n lg n) time. |




